

Whatever could be reused, should be. It's one of the first commandments we learn when we begin to study programming. If you have a reusable piece of code, make it a function; if you have a reusable set of functions, make it a library. If more than one segment of your project uses it, create a shared library. And if you need to change something in this library... aye, there's the rub.
So what to do with a library, used by several independent services within one project that might be modified by each of them?
Approach 1: Copy'n'Paste
The easiest way is just to place a copy of the library into each project.
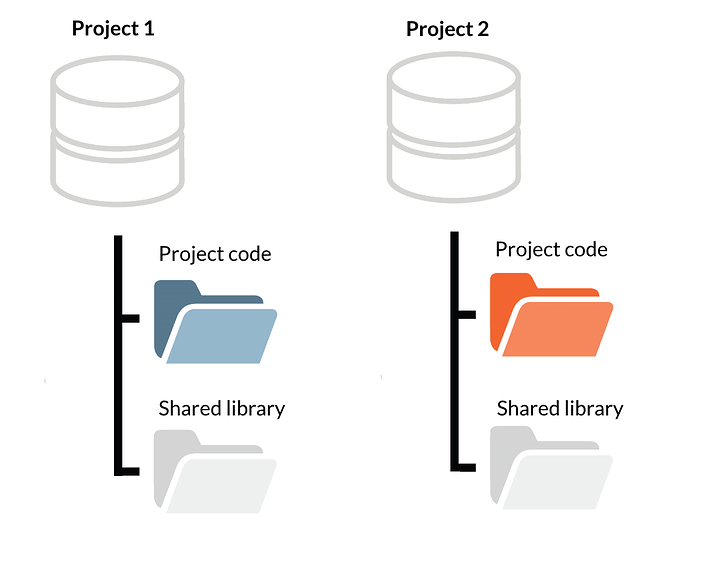
However, this is a clear contradiction to the first commandment, which leads to supporting multiple versions of the same library, and is often frowned upon. So we won't do that.
Pros:
- Simple
Cons:
- Inherently wrong
- Creates multiple versions of the same library
Approach 2: Multirepo
A standard, socially acceptable solution is to keep the shared library in a separate repository and use it as a dependency when necessary. Such setup, when each component has a unique repository, is sometimes referred to as 'multirepo'.
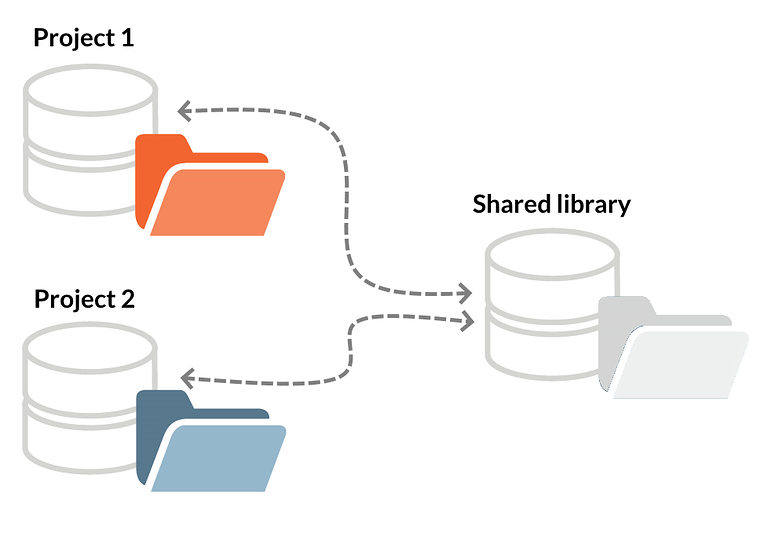
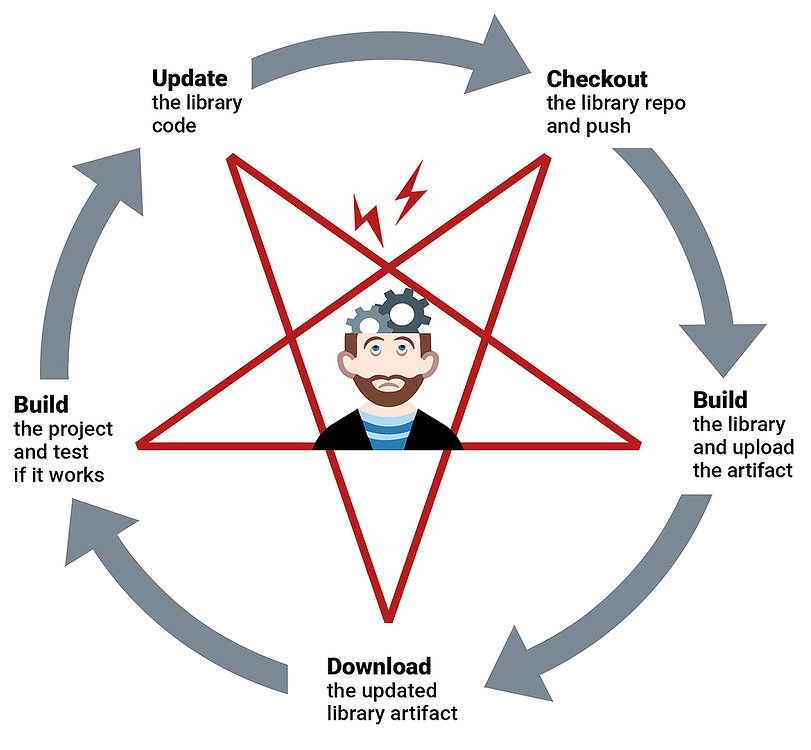
To update a shared component, you just check out that repository, push the updates, then check out your project repository and move on. Some back and forth may happen several times a day (especially if you have more than one shared library), but it's not a nightmare... as long as an interpreted programming language, like JavaScript, is utilized. For compiled languages, such as Java, that use build tools like Maven, the process is more complex:
- Check out the library repository;
- Push the changes;
- Have the CI build the library, test and upload the artifact;
- Download the updated library artifact to the project;
- Test if your updates work;
- If not - go back to the first step.
Pros:
- Simple
Cons:
- Updating shared components and the main project in parallel is troublesome
Approach 3: Git Submodules
Invented by the best minds in modern software engineering, Git has a solution to this, called 'git submodules'. It allows embedding one repository inside another, like Russian nesting dolls.
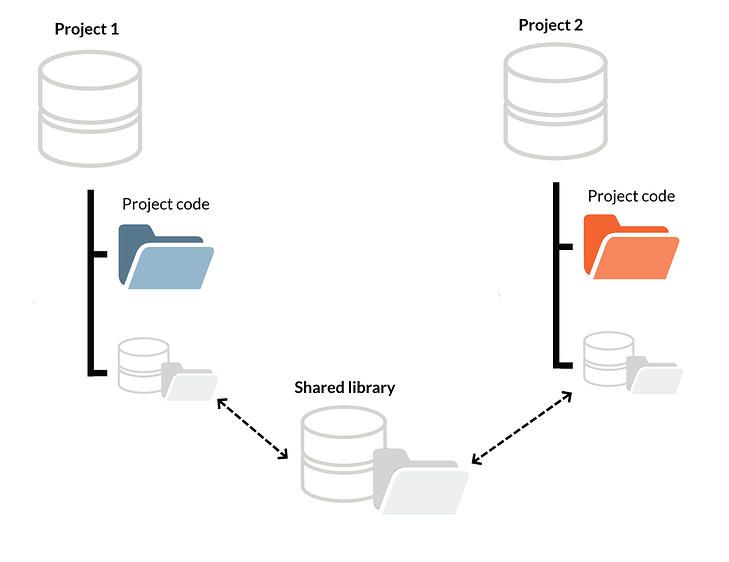
However, if you search, what people say about it, you will find a lot of comments like that:
What's the catch? It's in the nature of git submodules: each submodule remains a separate repository. You don't have to check it out separately, but you can't treat it as part of the main repository. If one of the updated files belongs to a submodule, update the submodule first with a special command, then commit the new dependency to the project repository, and only then commit the rest of the update. Doing it in the wrong way will break it all, and may even cause you to lose your code.
Pros:
- Native Git solution
- All code is in one directory
Cons:
- Client-side - each developer has to set up and maintain it for himself;
- Need special commands to work with module (shared) repositories;
- Could be easily broken.
Approach 4: Monorepo
There were numerous attempts to improve Git Submodules ('git subtree', 'git subrepo' - to name a few), but in the past several years the industry seems to have abandoned this. Large companies, such as Google, Facebook, and Twitter, started gathering all their codebases in massive repositories, so-called "monorepos".
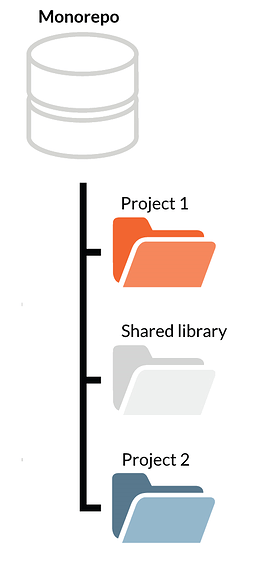
They tried to remedy the problem by storing all projects and libraries in the same repository. Instead, they got enormous repositories, where git status took minutes, and git clone might have taken hours. Another issue was the organizational mess when hundreds of developers simultaneously committed to the same repository.
 (source)
(source)
So the next step was to develop sophisticated tools ('Basel' for Google, 'Pants' for Twitter) to make monorepos function.
Pros:
- All code (in theory) accessible to every project
Cons:
- Scalability
- Hardware resources gluttony
- Needs special tooling
Approach 5: Git X-Modules
While dozens of engineers struggle online in the monorepo/multirepo battles, another approach is possible -- Git X-Modules. It's similar to Git Submodules, but has a very important difference: the repositories are nested on the server's side.
For the end-user, it's just a regular repository, with all code needed for his or her project (and nothing except that). He or she makes all updates with one atomic commit to such repository, and they are distributed automatically on the server between the project and the shared libraries.
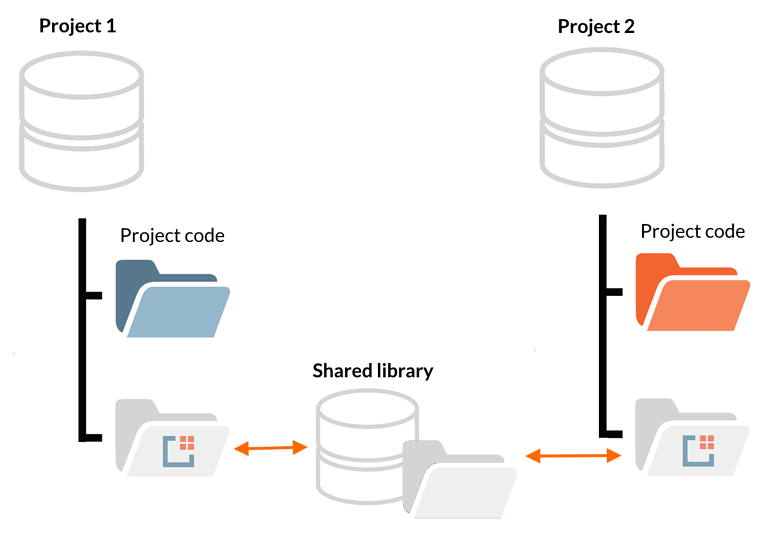
In fact, one can build a monorepo this way as well -- keeping all original repositories independent and intact.
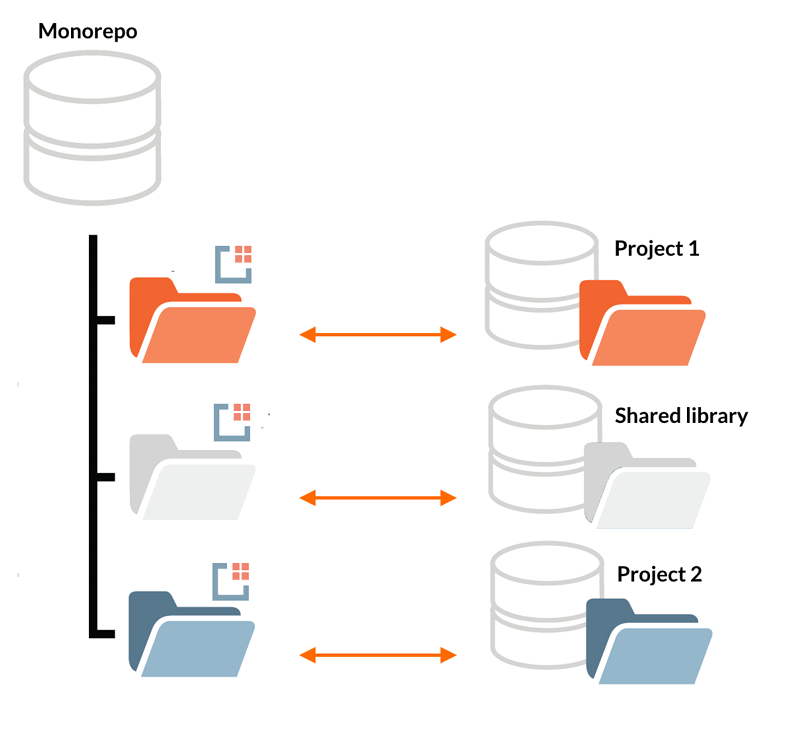
This software is still in the beta stage, however, a command-line tool and a plugin for Bitbucket Server/Data Center are available for download. Other implementations are coming soon.
Pros:
- No overhead to end-users - only standard Git commands
- Leaves the original repositories intact
- Can combine complete repositories or parts of them
Cons:
- Beta stage
- So far - only available for self-hosted Git servers
Now, what is your opinion? Which approach is more likely to lead, and why? What's your story of working with code, split between multiple repositories?



